EmoSen: Generating Sentiment and Emotion Controlled Responses in a Multimodal Dialogue System
Abstract
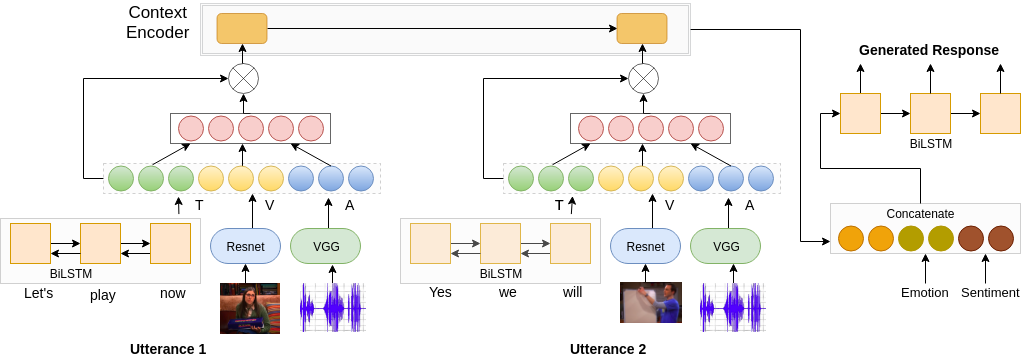
An important skill for effective communication is the ability to express specific sentiment and emotion in a conversation. It is desirable for any robust dialogue system to handle the combined effect of both sentiment and emotion while generating responses to provide a better experience and concurrently increase user satisfaction. Previously, research on either emotion or sentiment controlled dialogue generation has shown impressive performance, but the simultaneous effect of both is still unexplored. The existing dialogue systems are majorly based on unimodal sources, predominantly the text, and thereby cannot utilize the information present in the other sources such as video, audio, image etc. In this work, we present a first large scale benchmark Sentiment Emotion aware MultimodalDialogue (SEMD) dataset for the task of sentiment and emotion controlled dialogue generation. The SEMD dataset consists of55k conversations from 10 TV shows having text, audio and video information. To utilize multimodal information we propose multimodal attention based conditional variational autoencoder (M-CVAE) that outperforms several sophisticated multimodal baselines. Quantitative and qualitative analysis show that multimodality along with contextual information plays an essential role in generating coherent and diverse responses for any given emotion and sentiment.